FunAudio-ASR 正式发布
[summary]
通义实验室新一代端到端语音识别大模型
基于领先的自研语音技术
具备卓越的上下文感知和高精度语音转写能力[header-link]
https://bailian.console.aliyun.com/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.1a947b08ZcVbcp&tab=doc#/doc/?type=model&url=2842554
API 体验链接
我们正式推出 FunAudio-ASR —— 一款专为解决企业落地难题而生的端到端语音识别大模型。它不仅拥有高精度的通用识别能力,还通过创新的 Context 增强模块,针对性优化了“幻觉”、“串语种”等工业场景中的关键问题。
Context 增强模块,优化“幻觉”与“串语种”问题
在语音大模型落地过程中,我们发现“幻觉”与“串语种”是两类高频出现的典型问题。 其根源在于 LLM 缺乏准确、稳定的上下文引导。
为此,我们创新性地设计了 Context 增强模块 —— 一个轻量、高效的前端结构,通过 CTC 解码器快速生成第一遍转写文本,并将该结果作为上下文信息输入 LLM,辅助其更准确地理解音频内容。
由于 CTC 是轻量化、非自回归结构,该模块几乎不增加额外推理耗时,却带来了双重优化效果:
1. 优化“幻觉”问题
相比于文本 LLM,语音大模型的“幻觉”问题尤为突出。这是因为声学特征与文本特征在向量空间上天然存在差异,导致模型在“听”完音频后,容易“脑补”出大量不存在的内容。
尽管通过训练将声学特征对齐到文本特征空间,由于声学特征 Embedding 与真实的文本 Embedding 仍然存在这一定的差距,这会导致LLM在生成文本时发生幻觉的现象。
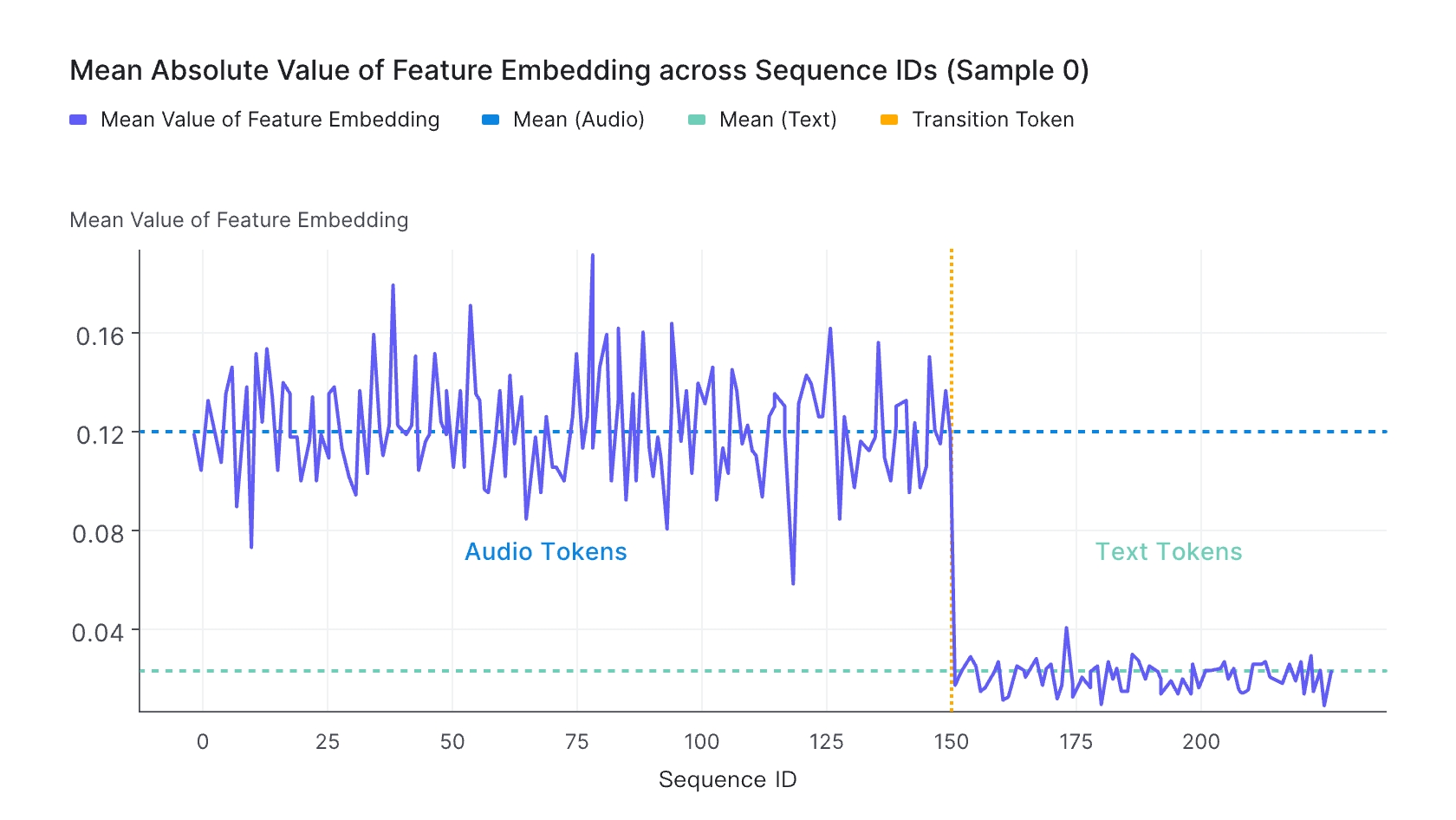
- 声学特征Embedding与真实的文本Embedding分布差异(图片来源:https://arxiv.org/pdf/2410.18908)
我们通过探索发现,给语音大模型提供必要的上下文,可以减少文本生产时候的幻觉现象。
为此,我们设计了 Context 增强模块:该模块通过 CTC 解码器快速生成第一遍解码文本,并将该结果作为上下文信息输入 LLM,辅助其理解音频内容。由于 CTC 结构轻量且为非自回归模型,几乎不增加额外推理耗时。
此外,我们观察到幻觉问题在高噪声场景中更易发生,因此在训练数据中加入了大量仿真数据。我们构建了一个包含 28 条易触发幻觉音频的测试集,经优化后,幻觉率从78.5% 下降至 10.7%。
2. 缓解“串语种”问题
“串语种”是语音大模型落地中的另一类典型问题。具体表现为:输入音频内容为英文,模型输出却为中文文本。这是因为文本 LLM 本身具备翻译能力,在声学特征映射不够精确时,模型可能在推理过程中“自动启动”翻译功能,从而影响语音识别的准确性。
在 FunAudio-ASR 的 Context 增强模块中,CTC 解码器经过高质量数据训练,本身发生串语种的概率极低。通过将 CTC 的第一遍解码结果作为 Prompt 输入给 LLM,可有效引导模型聚焦于语音识别任务,缓解“翻译”行为的发生。
模型性能对比
我们将 FunAudio-ASR 与行业典型模型及开源 SOTA 模型进行对比测试,重点关注语音识别在远场、嘈杂背景等挑战性场景下的表现。为此,我们构建了五大类测试集。
FunAudio-ASR-nano 为轻量化版本,在保持较高识别准确率的同时,具备更低的推理成本,适合对资源敏感的部署环境。
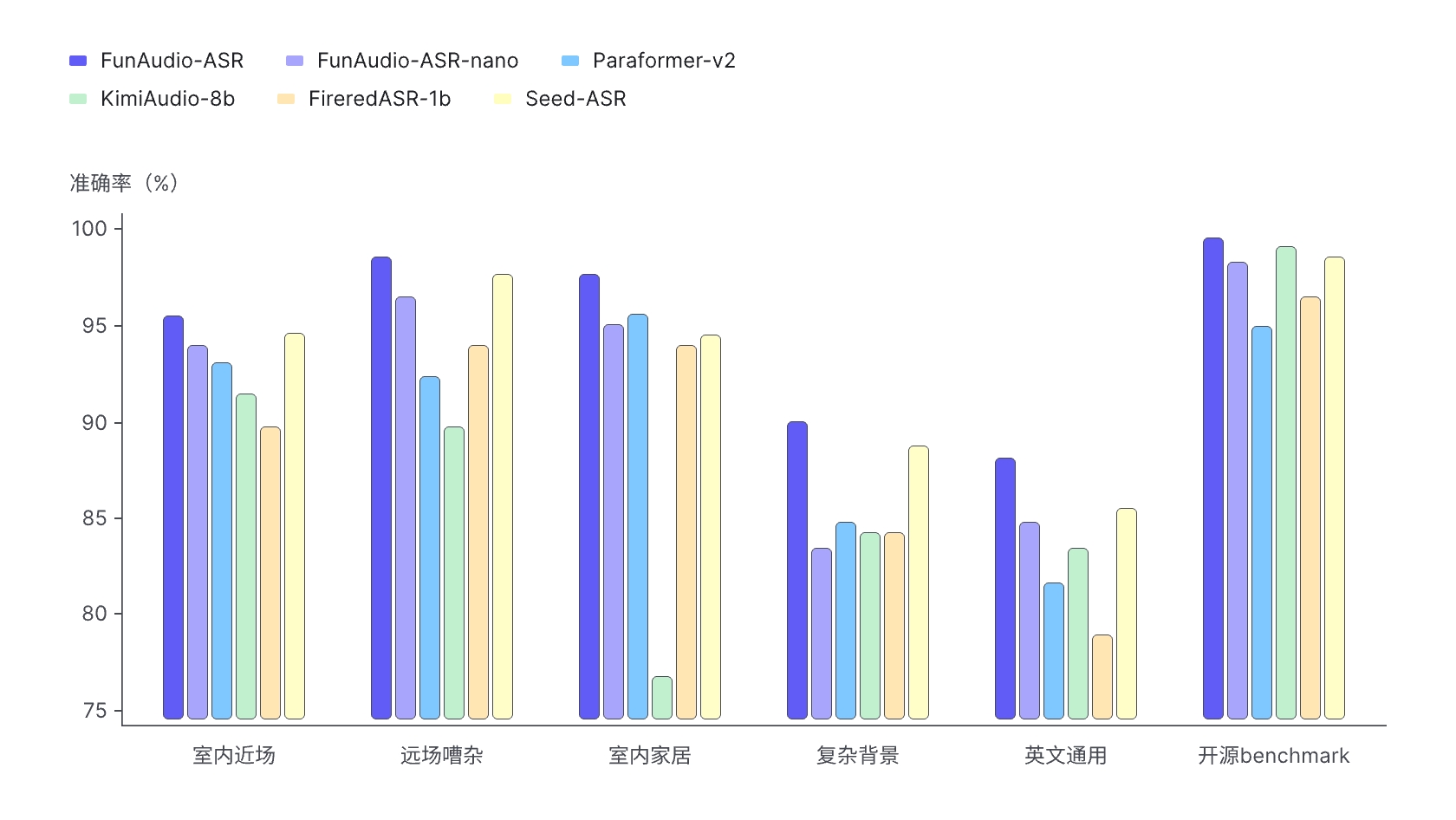
行业定制化能力提升
在 ASR 的工业落地中,个性化定制是必不可少的技术。所谓定制化,是指在识别过程中对特定词/短语(如人名、地名、品牌、专业术语等)施加额外概率偏好,从而显著提高它们的识别召回率,同时尽量不损伤通用识别准确率。
当前行业主流做法,是将用户提供的领域词直接作为 Prompt 输入 LLM。该方法虽简单有效,但随着词量增加,干扰也随之上升,导致召回率下降——即“定制化能力衰减”。
我们的解决方案:RAG机制
为缓解这一问题,我们在 Context 增强结构中引入 RAG(检索增强生成)机制:
- 构建知识库:将用户配置的定制词构建成专属 RAG 库;
- 动态检索:依据 CTC 第一遍解码结果,从RAG库中抽取相关词汇;
- 精准注入:仅将相关词汇注入 LLM 的 Prompt 中,避免无关信息干扰。
该方案在不增加推理复杂度的前提下,将定制化上文数量扩充到上千个以上,并且保持较高的定制化识别效果。
领域词定制化能力对比表
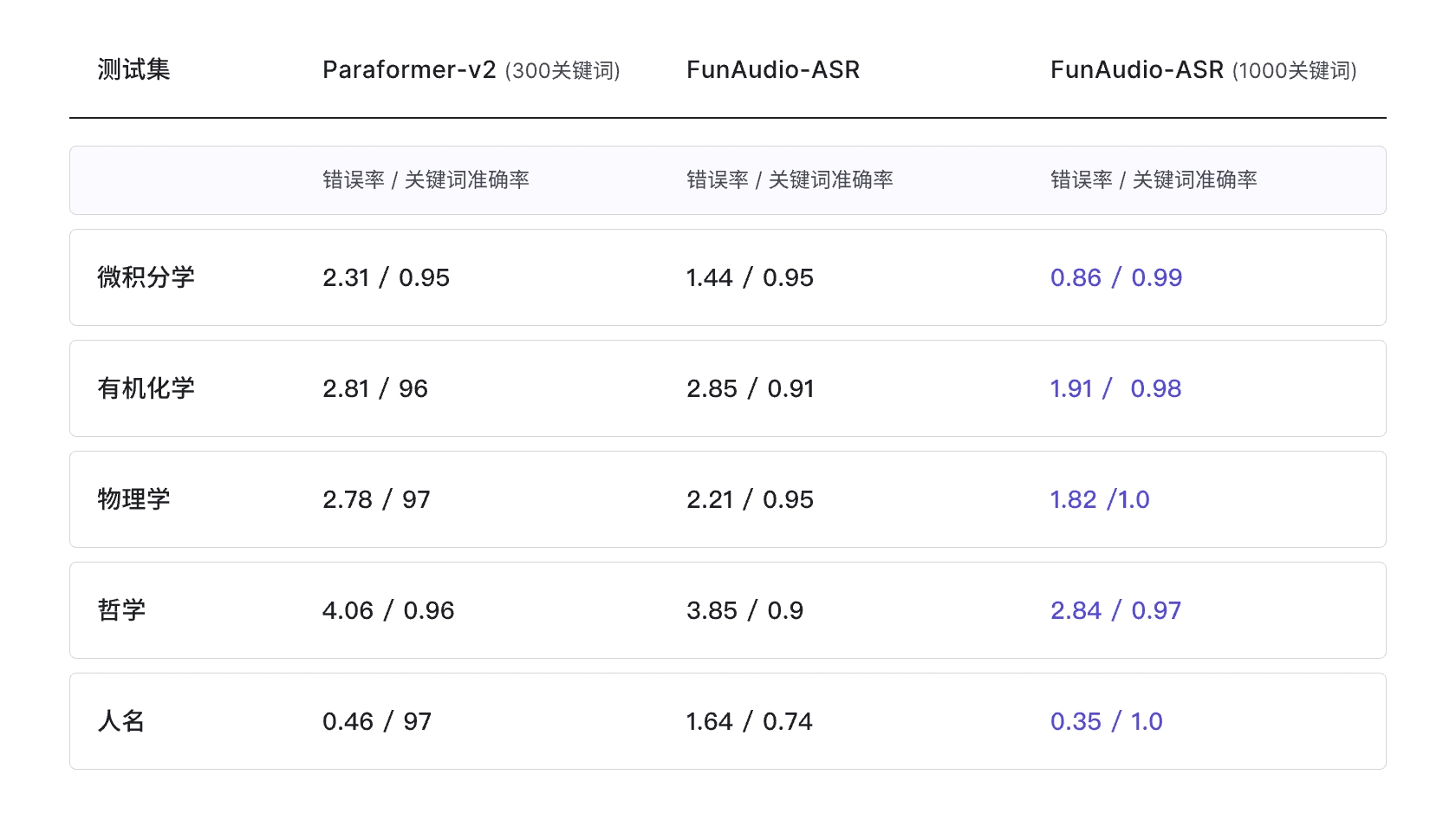
- 错误率:表示整条音频识别错误率,越低表示识别效果越好;关键词准确率:识别结果中,领域词识别的准确率,越高表示领域词识别越好。
- 效果验证:我们在微积分学、有机化学、物理学、哲学、人名等5个领域,选取了1000个专业词汇进行测试。FunAudio-ASR 在关键词准确率上表现优异,满足工业级定制化需求。