2025-12-02
Qwen3-VL-Flash上架百炼
[summary]
Qwen3系列小尺寸视觉理解模型
实现思考模式和非思考模式的有效融合
全面升级图像/视频理解,具备视觉2D/3D定位能力[header-link]
https://bailian.console.aliyun.com/?tab=model#/model-market/detail/qwen3-vl-flash
API 体验链接
自 Qwen3-VL 开源发布以来,该模型在全球AI开源社区中收获的的广泛认可!在9月底的Chatbot Arena子榜单Vision Arena中,Qwen3-VL位居第二,是视觉理解领域中的全球开源冠军;同时,Qwen3-VL还斩获纯文本赛道(Text Arena)的开源第一(全球第8),成为首个揽获纯文本和视觉两大领域同时开源第一的大模型。并且,Qwen3-VL还在 OpenRouter 图像处理榜单上以 48% 的市场份额跃升至全球第一。
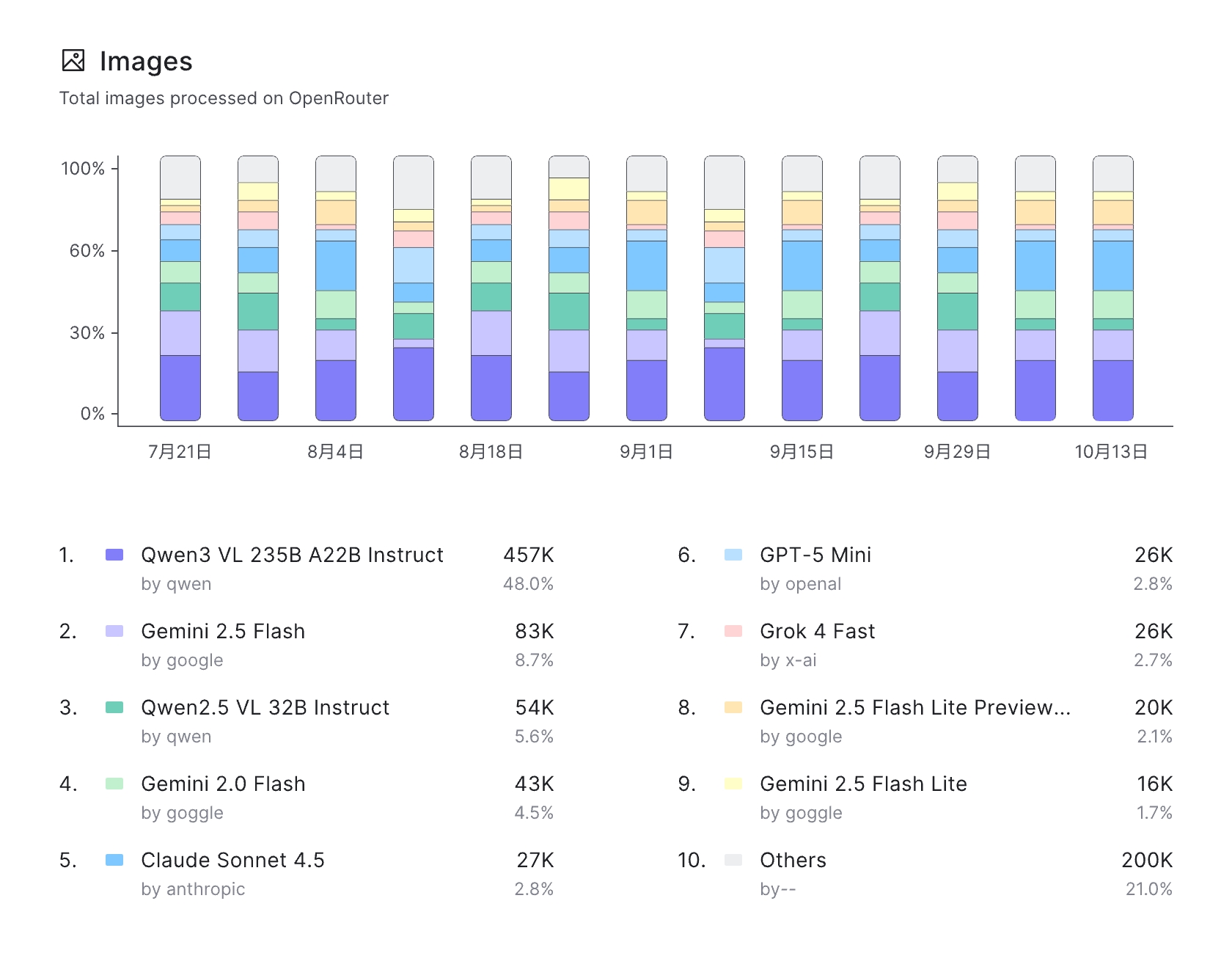
Qwen3-VL-Flash是Qwen3系列小尺寸视觉理解模型,实现思考模式和非思考模式的有效融合,效果优于开源版Qwen3-VL-30B-A3B,响应速度快。全面升级图像/视频理解,支持长视频长文档等超长上下文、空间感知与万物识别;具备视觉2D/3D定位能力,胜任复杂现实任务。
模型评测:qwen3-vl-flash效果超过上一代qwen2.5-vl-72b
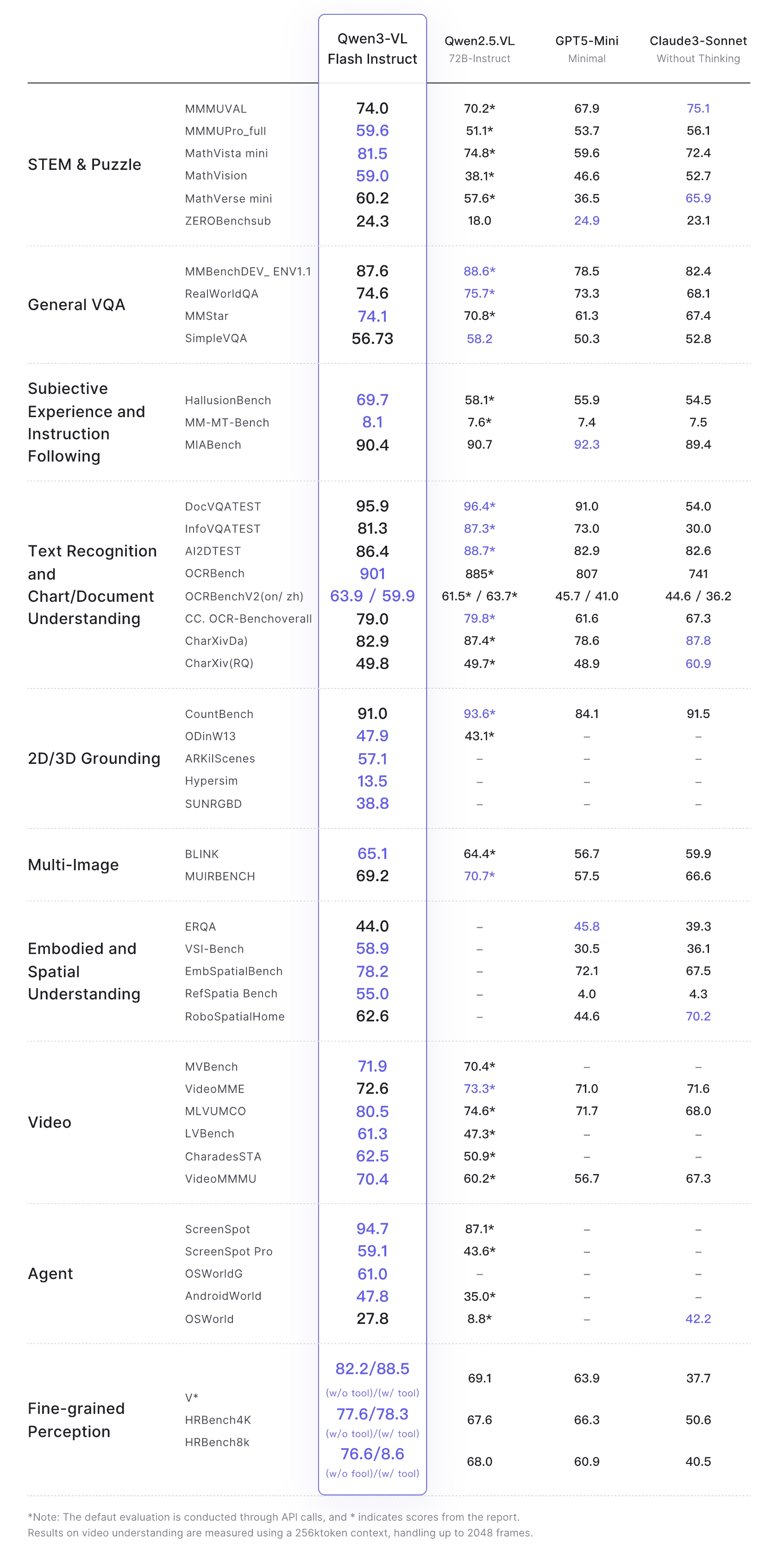
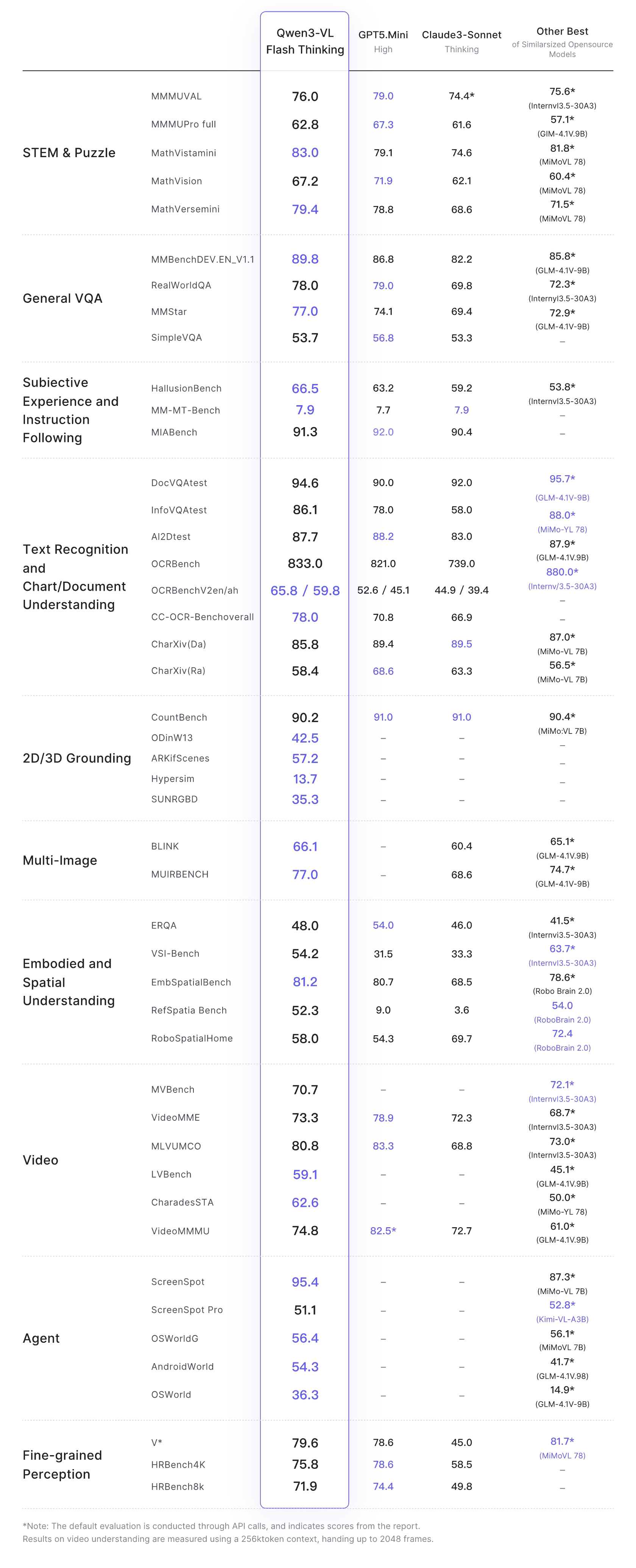
官方CookBook
Qwen3-VL发布后受到社区的广泛好评,官方也在最近推出了CookBook指南,这些 Cookbook 围绕真实场景设计,覆盖高精度文档解析、多语言自然场景 OCR、长视频理解、3D 物体定位、空间关系推理,以及面向移动端和计算机操作的智能体控制等核心能力,全面展现 Qwen3-VL 在复杂视觉语言任务中的强大表现。欢迎试用、反馈,并与我们一起拓展多模态大模型的应用边界。
相关资讯
Wan2.5系列模型正式发布
近日,我们在2025杭州云栖大会上发布 通义万相 Wan2.5 Preview 系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型,其中,通义万相2.5视频生成模型能生成和画面匹配的人声、音效和音乐BGM,首次实现音画同步的视频生成能力,进一步降低电影级视频创作的门槛。即日起,用户可在阿里云百炼平台调用API,或在通义万相官网直接体验。
2025/10/17
FunAudio-ASR 正式发布
我们正式推出 FunAudio-ASR —— 一款专为解决企业落地难题而生的端到端语音识别大模型。它不仅拥有高精度的通用识别能力,还通过创新的 Context 增强模块,针对性优化了“幻觉”、“串语种”等工业场景中的关键问题。
2025/9/16
通义DeepResearch模型、框架、方案全开源
我们推出了 通义千问深度研究,这是一个具有300亿总参数的代理大语言模型,每个令牌仅激活30亿参数。该模型由通义实验室开发,专门用于长期、深入的信息检索任务。通义-深度研究在一系列代理搜索基准测试中展示了最先进的性能,包括人类最后的考试、BrowserComp、BrowserComp-ZH、WebWalkerQA、GAIA、xbench-DeepSearch 和 FRAMES。
2025/9/16